We all know that in today’s world, data is the king, but we have data in different
forms, types, relational, non-relational, structured, unstructured manner. It becomes
difficult to process the data and keep it in a single format that can be easily
readable by the system, analytics and with proper context. ADF comes to the rescue
here.
What is ADF – Azure Data factory?
Definition:
ADF – Azure Data Factory is an ETL (Extract, Transform, Load) (Extract, Transform
and Load) tool (service) provided by Microsoft Azure.
- ADF is a 100% cloud based Managed Service by Azure, so you do not need to
worry about infrastructure setup.
- We can also connect to the on-premises data
store in ADF.
- It allows you to create, schedule, and manage data pipelines
that can move data between supported on-premises and cloud-based data stores.
- Azure Data Factory facilitates the extraction, transformation, and loading (ETL)
of data for analytics and reporting purposes.
How does Azure Data Factory (ADF) work?
There are three main processes involved in ADF. Extract, Transform
and Load.
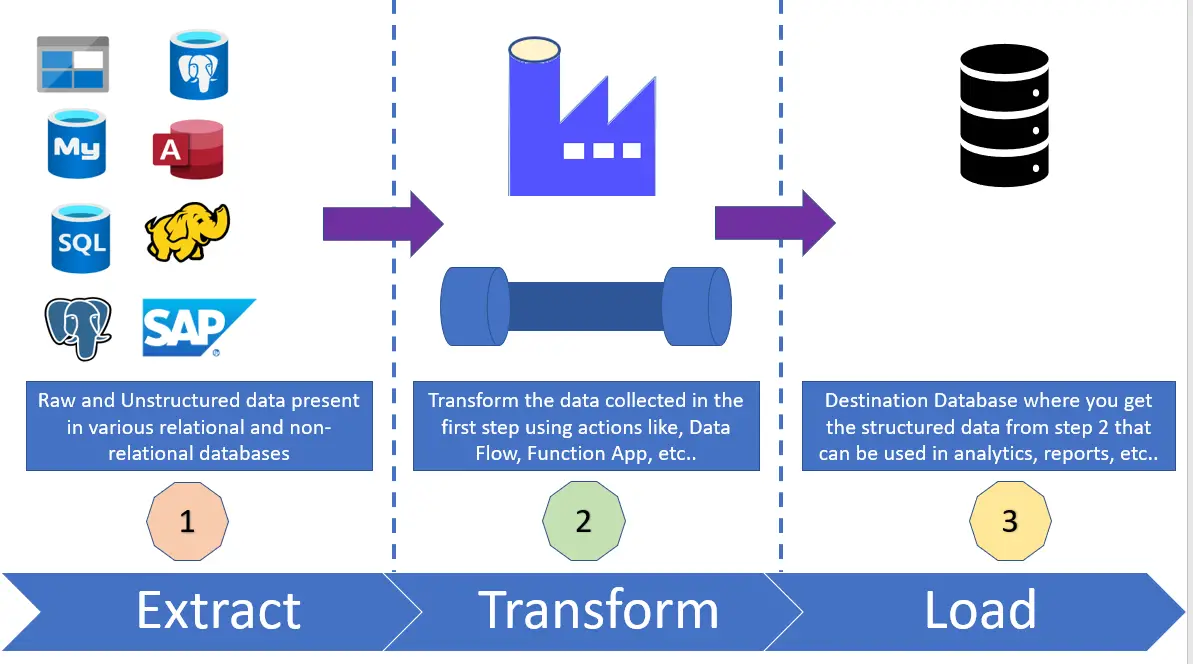
- Step 1 - Extract:
- All the data collection activities happen in this step.
- We fetch data from
various sources in this step. All the types of database sources are supported in
ADF.
- Data Sources can include databases, flat files, APIs, logs, and more
- Data can be structured, non-structured, relational, non-relational data.
- Step 2 – Transform:
- Once we collect (extract) the data, it is time to process that data to meet the
requirements of the target system, which happens in this step (Transform).
- Transformation
tasks include
- Data cleansing - removing or correcting errors
- Data enrichment - adding
additional information
- Data aggregation (summarizing data)
- Data formatting
- Data Converting
-
Data filtering
- Step 3 – Load:
- As part of this step, we load the transformed data into the target database system
which is typically a data
warehouse, data mart,
or another database.
- The data is organized into tables or proper structure to
make it more useful for reporting and analytics.
- As part of this step, we select
the data loading method like,
- Full Load
- Update
- Insert
- Upsert (Insert and Update)
- We also need to optimize the loading mechanism so that the loading takes minimal
time and enhances performance and efficiency.
- BULK upload is also an option
to speed up the data loading process.
What are the advantages of using ADF?
- Cloud Service (Server less): It is a 100%cloud based managed service so there
is no infrastructure needed to use this service.
- Connectors with scalability:
It can work with cloud and On-Premises data. ADF comes with more than 100 data connectors
to work with. ADF can handle large data processing in a way to avoid heavy investments
on On-Premises infrastructure.
- Code-Free: The pipeline you build up is
completely UI based, making it easy to create flows.
- Azure Compute: You
can run your code on any Azure Compute service like (Azure App Service, Azure Function)
-
SSIS (SQL Server Integration Services) in ADF: You can run SSIS package on
ADF as well as you can list and shift your SSIS packages
- Cost Effective:
It works on the Pay-As-You-Go model. You need to pay only what you use, and it can
be scaled more/less based on the demands.
- CI/CD – It comes with built-in
Git and CI/CD (Continuous Integration – Continuous Deployment) support.
- Schedule:
You can schedule your entire ADF Pipeline to a particular time and do not need to
trigger it manually every time.
- Monitor: You can keep track of all the
active executions. You can also see the successful and failed executions. Along
with this, you can also set notifications and alerts.
- Version Control and
Collaboration: ADF supports collaboration among development, testing, and production
environments. It includes version control features, making it easier for teams to
manage changes to data pipelines.
What are the Key Components of Azure Data Factory (ADF)?
- Pipelines –
- Pipelines are the main component of ADF.
- A pipeline is used to logically group the components together to perform a series
of tasks in a single run.
- Pipeline allows you to manage multiple activities as a single set instead of managing
each activity individually.
- Activities -
- An activity represents a single task within a pipeline.
- There are diverse
types of activities in ADF, each serving a specific purpose in the data integration
process. Here are some examples
- Copy Data Activity: The Copy Data activity is used for moving data from
a source data store to a destination data store.
- Data Flow Activity:
The Data Flow activity allows you to create and execute data transformations
using Azure Data Flow. Data Flow activities are useful for cleaning, transforming,
and enriching data.
- Web Activity: The Web activity enables you to
call a web service or a custom HTTP endpoint as part of your pipeline. This
can be useful for integrating with external APIs or triggering external processes.
-
ForEach Activity: The ForEach activity is a control flow activity that iterates
over a collection and executes a specified set of activities for each item
in the collection. It is useful for scenarios where you need to process data in
parallel or iterate over a list of values.
- If Condition Activity: The
If Condition activity is a control flow activity that allows you to execute a set
of activities based on a specified condition. It enables branching and decision-making
within the pipeline.
- Execute Pipeline Activity: The Execute Pipeline
activity allows you to invoke another pipeline as a sub-pipeline within the
current pipeline.
- Lookup Activity: The Lookup activity is used to retrieve data from a specified
data store.
- Datasets - Datasets are the data structures within the database, which
point to the data you want to use in your activities as inputs or outputs.
-
Linked Service - Linked service defines the connection information to a data
store or Azure compute service.
- Integration Runtimes - An integration
runtime component provides compute infrastructure that allows data movement and data
transformation activities to be carried out in various environments. Integration
Runtimes play a vital role in the pipeline executions, specifically when the data
movement is in different data stores and data processing is in different compute
environments.
- Triggers - Triggers define when and how pipelines should
run. Here are the main types of triggers in Azure Data Factory:
- Schedule Trigger:
- Description: Schedule triggers enable you to run pipelines on a predefined
schedule, such as daily, hourly, or weekly. You can also specify the time zone.
-
Use Cases: Daily data extraction, hourly data synchronization, weekly data
aggregation.
- Tumbling Window Trigger:
- Description: Tumbling window triggers allow you to run pipelines at regular
intervals defined by a fixed time window.
- Use Cases: Running a pipeline every 15 minutes during business hours, processing
data in fixed time intervals.
- Event-Based Trigger:
- Description: Event-based triggers allow you to trigger pipelines based
on events that occur in external systems. This can include file arrivals, blob
creations, or HTTP events.
- Use Cases: Running a pipeline when a new file
is added to a storage account, triggering a pipeline in response to an external
API call.
- Data Driven Trigger:
- Description: Data-driven triggers enable you to trigger pipelines based
on the availability of new data. You can define a data-driven event by specifying
a dataset and defining a condition based on the data's presence or changes.
-
Use Cases: Triggering a pipeline when new data is available in a source system,
running a pipeline when data in a specific table is modified.
What is the Purpose of Azure Data Factory?
- Data Integration
- Data Movement: ADF can move data between various data stores in a secure,
efficient, and scalable manner. This includes transferring data across different
cloud services and between cloud-based and on-premises data stores.
- Data
Transformation: It enables the transformation of data using compute services
such as Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics, and Azure Machine
Learning.
- ETL and ELT Processes
- ETL (Extract, Transform, Load): ADF can extract data from various sources,
transform it (clean, aggregate, join, etc.), and then load it into a data store
or warehouse for analysis.
- ELT (Extract, Load, Transform): It also supports
ELT processes, where data is first extracted and loaded, and then transformed within
the data warehouse.
- Data Orchestration and Workflow Automation
- Orchestrating Data Flows: ADF provides capabilities to create complex workflows
for data movement and transformation. These workflows can be scheduled and automated,
allowing for regular processing of data pipelines.
- Managing Dependencies:
It handles dependencies between various data processing steps in a workflow, ensuring
that tasks are executed in the correct order.
- Cloud-based Data Integration Solution
- Leveraging Cloud Scalability and Flexibility: As a cloud service, ADF offers
scalability to handle large volumes of data and the flexibility to integrate with
various cloud services and data stores.
- Data Modernization and Migration
- Modernizing Data Platforms: ADF is often used in data modernization initiatives,
helping businesses move from legacy systems to modern cloud-based data platforms.
-
Data Migration: It facilitates the migration of data to the cloud, useful
in scenarios like moving data to Azure for advanced analytics and AI capabilities.
- Support for Multiple Data Formats and Protocols
- Diverse Data Stores: ADF supports a wide range of data stores and formats,
making it versatile for different data integration needs.
- Secure Data Transfer:
It ensures secure data transfer with encryption and integration with Azure security
measures.
- Analytics and Business Intelligence
- Preparing Data for Analytics: By processing and transforming data, ADF prepares
data for analytical processing and business intelligence (BI) applications.
-
Integration with Analytical Tools: ADF integrates smoothly with Azure Synapse
Analytics, Power BI, and other analytical tools, enabling end-to-end data processing
and analysis solutions.